Mirage A Multi-Level Superoptimizer for Tensor Programs 简记
Mirage 是 CMU 贾志豪组搞的一个 ML Compiler,输入是一个计算图子图(子图中的算子来自一个预定义的算子集合),输出是优化后的 cuda 程序,所作的优化在效果上等价于一系列优化的结合,包括但不限于图变换 (graph rewrite) 和算子融合 (operator fusion)。
Mirage 和之前的算子级别或图级别的 ML Compiler 的不同之处在于,之前的 ML Compiler 的优化方法大多是 deductive program synthesis (一般称为 term rewrite),也就是 graph rewrite、loop rewrite/schedule 之类的方法,从原程序出发,通过一系列等价变换 (rewrite-rules, schedule-primitives, …),得到新的程序;而 Mirage 用的是 inductive program synthesis (一般称为 program synthesis……),根据语法 (算子集合) 直接去构造程序,通过一些方法 (通常是 SMT Solver) 来验证所构造的程序和原程序的等价性。ASPLOS’22 的 Rake (paper, code) 和 ASPLOS’24 的 Hydride (paper, code) 也用了 program synthesis 的方法来优化向量化的 Halide 程序在 x86 CPU, ARM CPU 和 Hexagon DSP/NPU 上的性能。
Mu-Graph
Mirage 的核心是一个 multi-level 的计算图表示,称为 mu-graph。mu-graph 包含三个层级,kernel-graph、block-graph 和 thread-graph,分别对应 cuda 程序执行的三个层级。
- kernel-graph 的张量位于全局内存,算子包含两种,一种是预定义算子 (pre-defined operator),另一种是合成算子 (graph-defined operator)。其中预定义算子会直接对应 vendor-library 的 kernel,例如 matmul 对应 cublas 里的 gemm,而合成算子则会包含一个 block-graph。
- block-graph 的张量位于共享内存,算子包含预定义算子和合成算子。其中预定算子会对应 CUTLASS 或者 ThunderKittens 等 CUDA 组件库中封装好的共享内存上的一些操作(例如矩阵乘等),而合成算子会包含一个 thread-graph。block-graph 主要包含下面的属性来表示程序并行切分的信息:
- imap: grid-dims/spatial-dims 到 input tensor dims 的映射。
- omap: grid-dims/spatial-dims 到 output tensor dims 的映射。
- fmap: for-loop-dims/temporal-dims 到 input iterator dims / output accumulator dims 的映射。
- thread-graph 的张量位于寄存器,算子只包含预定义算子,对应封装好的寄存器上的一些操作。
下图展示了原程序为 GQA 计算所得到的一个 mu-graph: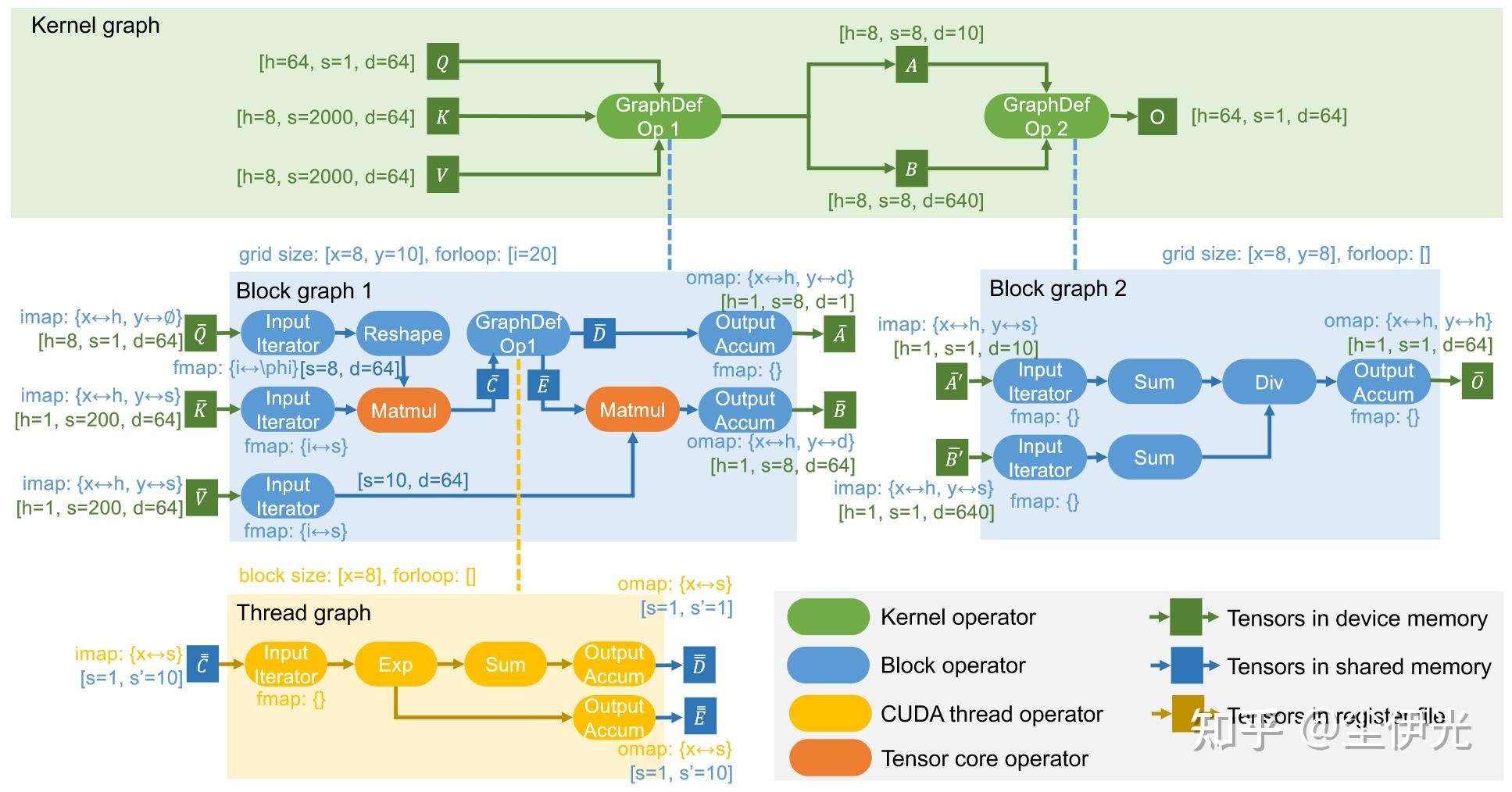
Synthesis
program synthesis 的主要流程如下图所示: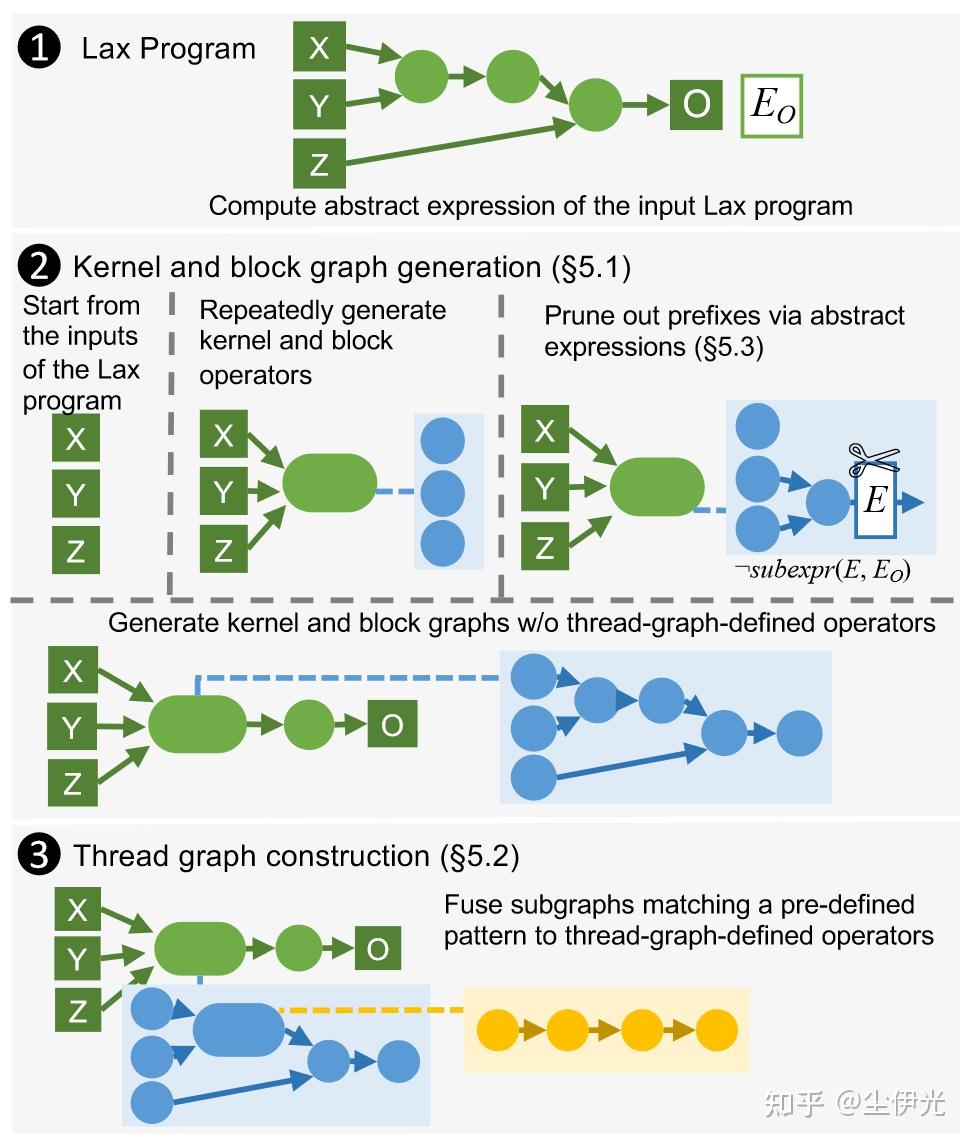
Mirage 在 synthesis 过程中,维护一个 prefix kernel-graph(有算子数量限制),每次枚举一个算子加入(枚举 matmul, exp, add, …, 合成算子),枚举到了合成算子,会递归进行 block-graph 的 synthesis (会枚举不同的 grid-dims 和 for-loop-dims),以此类推。Mirage 会将 mu-graph 转换为 canonical form 来过滤重复的 mu-graph。
Pruning & Verification
program synthesis 的问题主要在于速度比较慢,慢的原因主要有两点,一是枚举过程中有些前缀程序可能之后永远都无法扩展到和原程序等价,搜索这些就是浪费时间,二是最终验证合成的程序和原程序的等价性一般需要用到 SMT Solver,这个太慢了,特别是针对规模较大的 tensor program。针对此,Mirage 也提出了两个优化,一个是基于 abstract expression 的剪枝,一个是基于 finite field random test 的等价性验证。
Mirage 会将搜索过程中的 prefix graph 的算子的表达式简化为 abstract expression,主要是简化了 matmul 和 reduction 等计算的表示: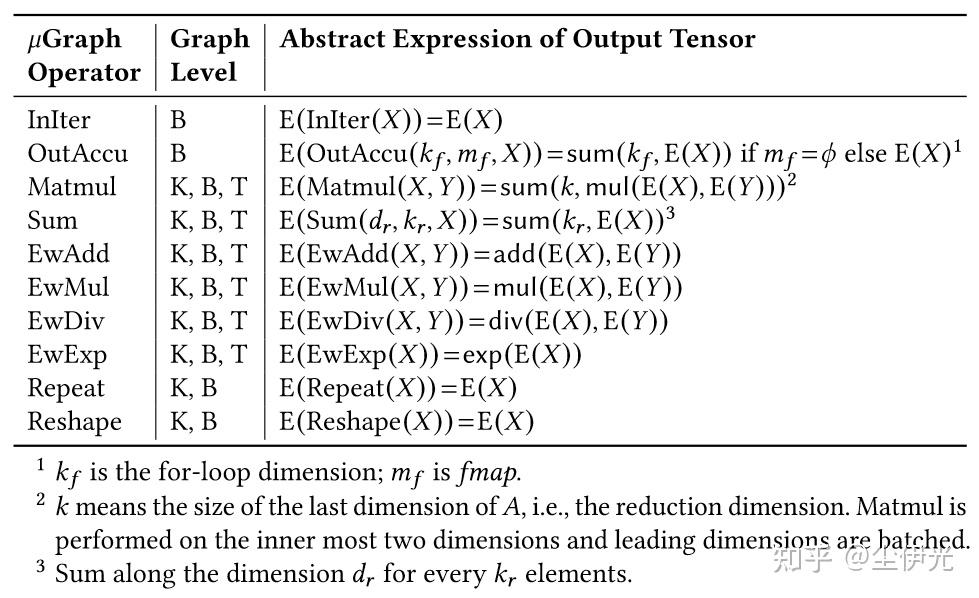
借助公理集合 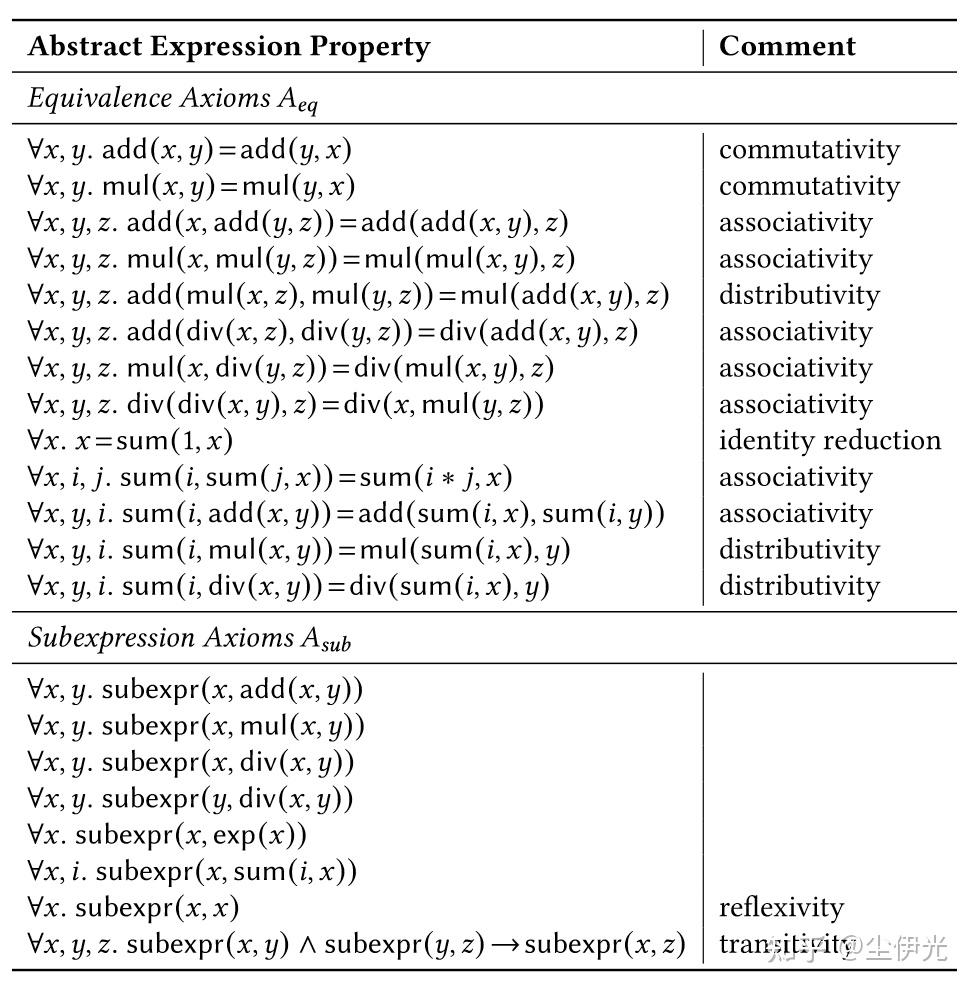
为了验证合成的 mu-graph 和原 mu-graph 的等价性,Mirage 在 finite filed 
至于根据 mu-graph 生成实际的 cuda 程序,Mirage 也做了不少的优化,在文档里有详细的描述,之后可能会再写个博客分析一下。
Disscussion
我个人还是挺喜欢 Mirage 这个工作的,它通过 inductive program synthesis 巧妙地将 kernel-level 和 block-level (以及 thread-level) 的优化空间进行了融合统一,效果也确实挺不错的(我之前其实也有考虑将这几个层级进行统一优化,不过一直拘泥于 deductive synthesis 的思路,很难搞出实际可用的解决方案)。不过 Mirage 还是有几个个人感觉比较局限或者说需要改进的点:
- 优化时间:论文的 Section 7.4 有提到,在 block-graph 的算子数量达到 7 的时候(这个是搜索出论文 Figure 4 的优化后的 GQA 的必要数量),搜索时间基本就要破一个小时了(当然这个在一众 Tuning-based ML Compiler 里其实算比较快的了……)。
- 对动态形状的支持:目前 Mirage 应该是只支持静态形状输入,个人希望搜索出的 mu-graph 可以直接扩展到支持动态形状输入(保持 block-graph 的 shape 不变)。
- 支持的程序:目前 Mirage 的 finite field random test 要求的 mu-graph 一条路径上至多只有一个 exp,不然难以推导出论文中的 Theorem 3.
- 算子扩展:目前 Mirage 支持的算子类型比较有限(连 max 都没有,所以 Mirage 写的 Attention 都是没有使用 numerical stable softmax 的版本,基本不会在生产环境中使用),而且扩展起来挺麻烦的,添加一个新算子需要实现其对应的 abstraction expression(可能还需要添加新的公理到
和 中)以及在 finite field 上的操作,基本上只能由开发者进行扩展(而且有些算子还真不一定好加进来,比如 max ……)。我觉得这个是最大的问题。