Stream-K 和 Lean-Attention
这两天看了一下 Stream-K 和 Lean-Attention,简单总结一下。
Stream-K
Stream-K 是英伟达提出的一个 HPC 算法,主要是为了解决 GPU 上优化 GEMM 所使用的传统的 Data-Parallel 以及 Split-K 算法所面对的 SM 利用率不稳定的问题。当然这个算法也可以用于优化其他的同时存在 spatial-loop 以及 reduce-loop 的算子。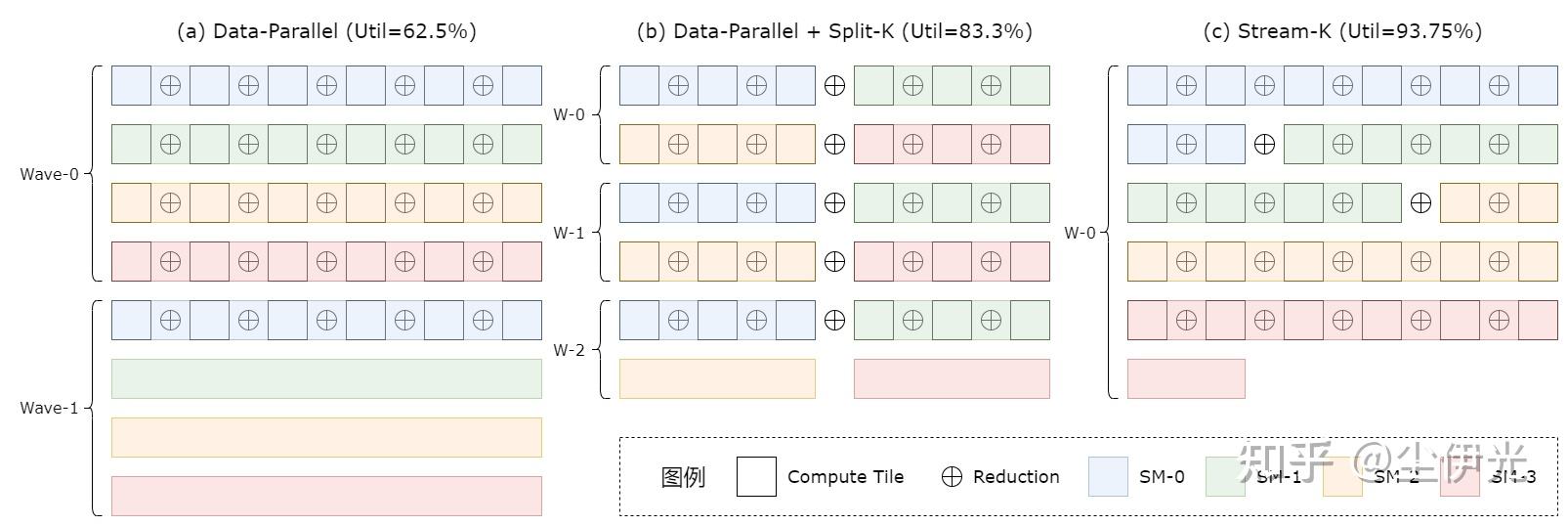
上图展示了这几个算法之间的直观思路。对于 GEMM 来说的话,每行代表一个 MN-tile (output-tile) 的计算,每行的每个白色方格代表一个 MNK-tile,
(a) 表示的是传统的 Data-Parallel 算法,只沿着不存在数据依赖的 MN 维度进行并行化,将各个 MN-tile 顺次分配给 GPU 上的 SM 进行计算,所有 SM 每计算一个 MN-tile 的过程被称为一个 Wave,不难看出在 Wave-1 的时候,SM-1、SM-2、SM-3 是完全闲置的,计算资源被浪费了,整个 GEMM 计算过程的 SM 利用率(Util)只有 62.5%。
(b) 表示的是在 (a) 的基础上加上 Split-K 算法,也就是在先对 MN 维度进行并行切分的基础上,再对 K 维度也进行并行。因为 MNK-tile 之间的累加操作(不考虑浮点误差的话)是满足结合律的,所以可以进行并行归约。和 (a) 相比,其 SM 利用率提高到了 83.3%。不过代价是计算同一个 MN-tile 的不同 SM 之间需要进行同步来累加各自计算的部分和(partial sum),并且同步归约的次数和整个 MNK 的规模成正比。
(c) 表示的是 Stream-K 算法,该算法将直接将 MNK 三个维度融合了之后统一考虑并行切分,将各个 MNK-tile 均分给各个 SM。该算法达到了 93.75% 的 SM 利用率,并且和 Split-K 相比,其同步归约的次数也更少,理论上不超过 GPU 的 SM 个数。
利用率分析
定量分析一下各个算法的 SM 利用率。假设各个 spatial-loop 经过切分后总的 tile 个数为
先定义一个辅助函数:
则 Data-Parallel 的 SM 利用率为:
Data-Parallel + Split-K 的利用率为(假设 Split-K 的切分个数为
Stream-K 的利用率为:

当
不难看出当
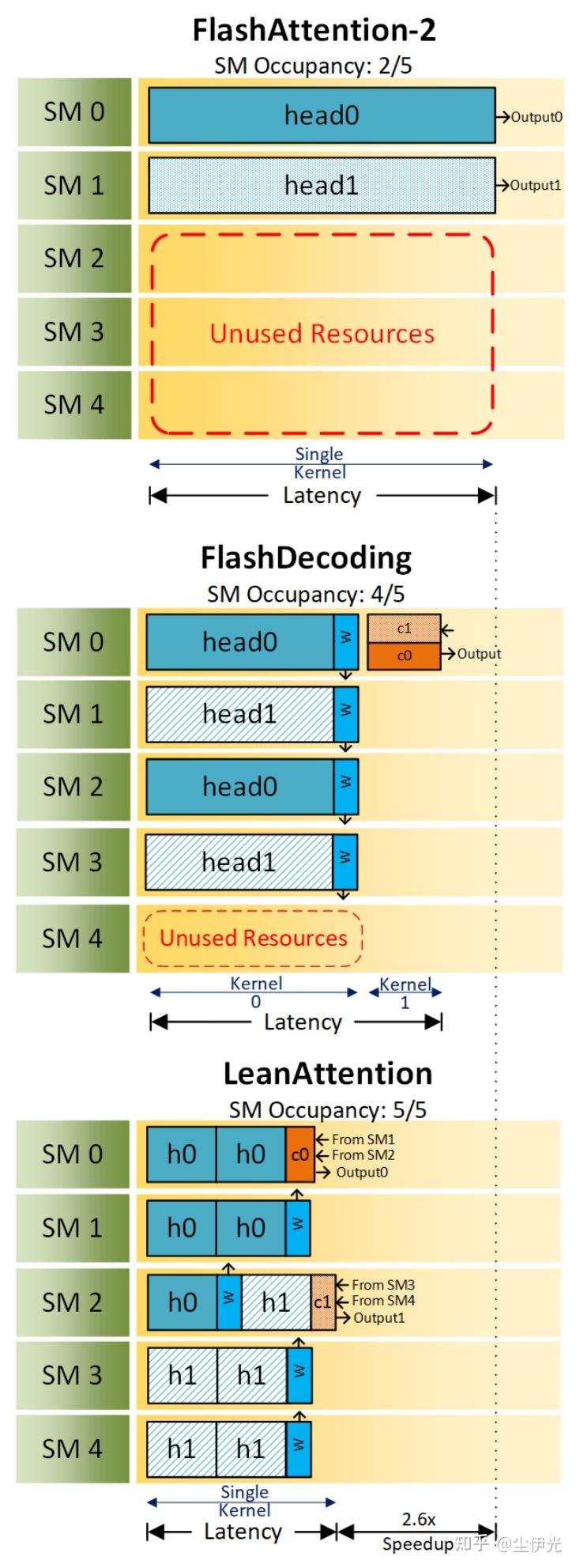
Lean-Attention
前文说过,Split-K 和 Stream-K 对于其他的同时存在 spatial-loop 和 reduce-loop 的算子来说也是适用的,比如 Flash-Attention-2。Flash-Decoding 就是 Split-K 在 Flash-Attention-2 上的应用,而最近挂在 arxiv 上的 Lean-Attention 则是 Stream-K 在 Flash-Attention-2 上的应用。Lean-Attention 原理较为简单,和 Flash-Decoding 一样利用了 online-softmax 满足结合律的特性,只是把优化用的 Split-K 换成了 Stream-K。