2023年你最喜欢的MLSys相关的工作是什么(回答)
2023 年 mlsys 相关的研究中,最有代表性的主题无疑是 llm inference,涌现了不少优秀的工作。llm training 和之前的 transformer-based model training 主要是 scale 上有区别,基本的分布式训练方法大同小异,感觉前两年也大致卷完了。但 llm inference 除了 scale 上的区别使得内存压力和计算压力增大以外,其自回归解码的性质也使得推理优化变得更加有趣。感觉喜欢的工作挺多的,就都简单列一下吧。
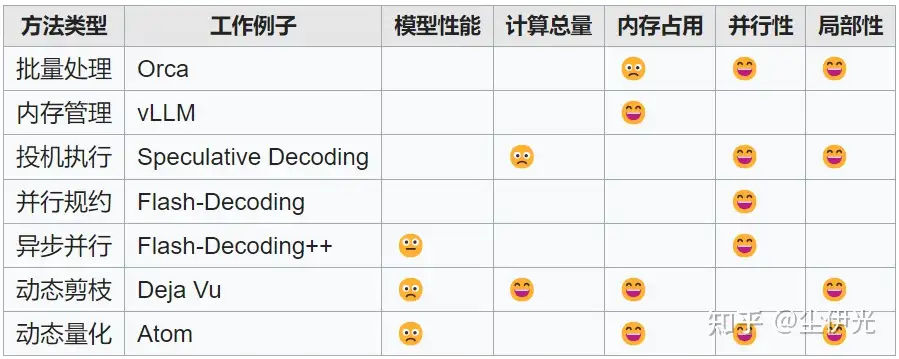
首先是 Continuous Batching,出处是 OSDI’22 的工作 Orca ,不过 “continuous batching” 这个名称还有大家比较熟悉的那个示意图出处好像是 2023 年的一个博客 How continuous batching enables 23x throughput in LLM inference while reducing p50 latency ,而且其大规模应用也在 2023 年,就勉强当作 2023 年的工作吧。主要贡献是通过细粒度的 batching 来改善了 llm serving 过程中硬件利用率问题。
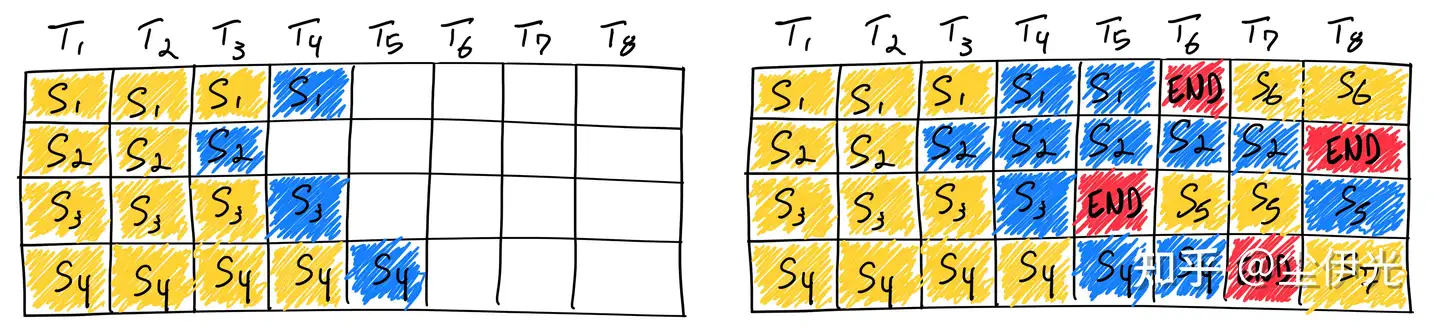
其次是 vLLM (SOSP’23 paper, code),是 Ion Stoica 门下 LLMSYS 小组的工作(之前搞出了 vicuna 和 fast-chat 的组),主要贡献是提出了 paged-attention(类似操作系统中虚拟分页的内存管理机制,以及配套的针对不连续 sequence 的 attention kernel),缓解了 llm decode 阶段动态增长的 kv-cache 造成的内存碎片问题(huggingface 采用 concat 来增长 kv-cache,拷贝开销大,外部碎片多;faster-transformer 为每个 kv-cache 预分配固定内存,内部碎片大),由此也增大了 serving 过程的 batching 容量上限,大大提高了吞吐。
然后是 Speculative Decoding (ICML’23 paper),Google 的工作,借助一个更小的 draft model 来快速生成多个 token,由原始 model 来一次性验证这些 token,相当于变相突破了 llm decode 阶段每次只生成单个 token 的限制,以一些冗余计算为代价提高了硬件利用率,从而提升性能。CMU 的 Catalyst 组的贾志豪&苗旭鹏的工作 SpecInfer (paper, code) 以 boost 方式训练ensemble draft model,推理时将多个 draft model 的输出组织成 token tree,用 tree attention 进行快速验证。还有 LLMSYS 组的 Lookahead Decoding (blog, code) 则是借助并行采样&验证来加速 token 生成,性质上类似于即时”训练”一个 n-gram draft model 的 speculative decoding,同样也是用冗余计算来换取硬件效率,不过因为没借助预先训练的 draft model,上限会略低一些。
最后是 Flash-Decoding (blog, code) 和 Flash-Decoding++ (paper),前者是 Tri Dao 组的,相当于 Flash-Attention-v3,后者则出自清华汪玉组、上交戴国浩组、初创公司”无问芯穹”(Infinigence-AI)。两者解决的问题基本都是在 batch 不够大的情况下,decode 阶段 attention 的 query-seq-len=1 导致的并行性低下的问题,解决的共同思路都是想办法将 key-value-seq 维度给并行化。flash-decoding 将 flash-attention-v2 的思路和常见的 parallel reduction 结合。而 flash-decoding++ 的思路则更有趣,通过适当选取一个 unified max value(具体 analysis 参见 paper),将 softmax 所施加的 key-value-seq 维度上的 reduce 依赖部分破除,效率会比 flash-decoding 的 parallel reduction 更高。此外,Luis Ceze 门下的 FlashInfer (project, code) 也为 llm inference 提供了非常高效的 kernel 实现。
上述的工作大多和 llm decode 阶段的特性有关。还有一些通过“压缩”模型来减少内存压力和计算压力的工作感觉也不错,比如几个借助动态稀疏性来推进 llm 本地化部署的工作:Tri Dao 组的 Deja Vu (ICML’23 paper, code),上交 IPADS 的 PowerInfer (paper, code),苹果的 LLM in a Flash (paper);还有 llm low-bit 动态量化的 state-of-the-art,Luis Ceze 门下的工作 Atom (paper, code)。
最后附上上述提到的部分工作关于各种系统要素的权衡: