Stable-Diffusion + ControlNet 的 UNet 网络结构剖析
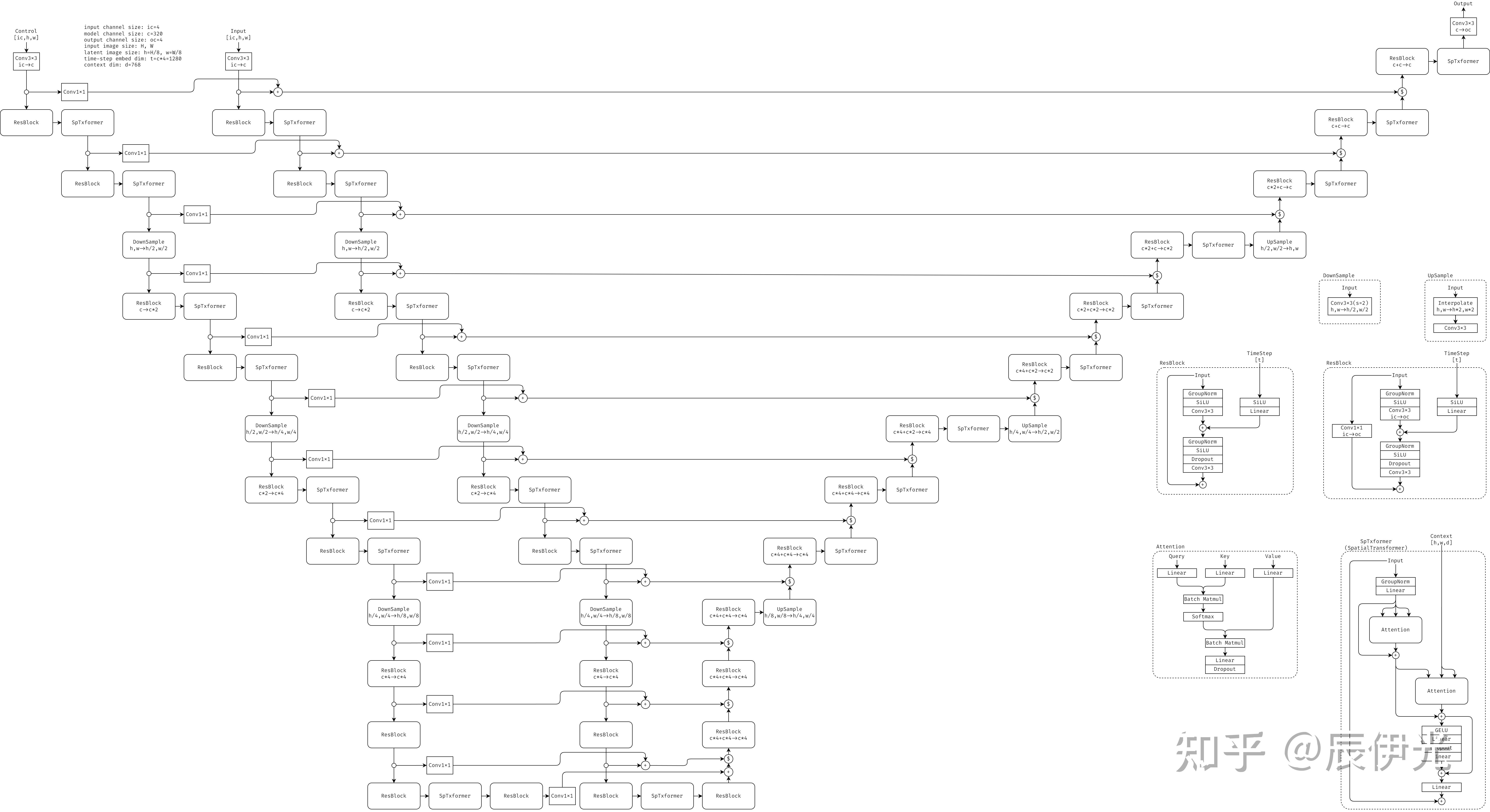
上图是 Stable-Diffusion (简称 SD) + 单个 ControlNet (简称 CN) 的 UNet 部分的整体结构 (SD1.5 或者 SD2.0 的结构,SDXL 的阶段数和各阶段层数会有些不同,不过大致上差不多)。其中 “$” 代表沿着 channel 维的 concat 操作。
假设用户指定生成一个 H x W 的图片,则 SD-UNet 的输入和输出一般是 H/8 x W/8 的 latent image。经过多轮 UNet 推理采样后,输出的 latent image 会经过一个 VAE Decoder 来生成最终的 H x W 大小的图片。如果是图生图,则用户输入的 H x W 的 image 会先经过一个 CLIP Encoder 来编码为 H/8 x W/8 的 latent image。
图中 DownSample, UpSample, Conv3x3(stride=2), Interpolate 方框内的 h1,w1->h2,w2 表示输入到输出的 image-size 的变化,部分 ResBlock, Conv3x3 方框内的 c1->c2 表示输入到输出的 channel-size 的变化。
SD-UNet 中第一个 Conv3x3 会将输入的 channel-size 由 4 升为 320,之后的下采样阶段会进行三次 DownSample,上采样阶段会进行三次 UpSample。每个 DownSample 会将 image height/width 减半,随后会跟着一个 ResBlock 来将 channel-size 加倍(除了第三个 DownSample 后的 ResBlock);UpSample 会将 image height/width 加倍,随后会跟着一个 ResBlock 来将 channel-size 减半(除了第一个 UpSample 后的 ResBlock)。
下采样阶段的每个 SpatialTransformer (SpTxformer) 和 DownSample 的输出会驻留在内存,和之后上采样阶段对应层级的 SpatialTransformer 或者 UpSample 的输出 concat 在一起,作为之后的 ResBlock 的输入,表现为图中的 12 个 skip-connection。
SD + n 个 CN 相当于把 SD 下采样阶段的网络复制 n 份(当然 SD 和各个 CN 的权重是不同的,输入的 latent-image 也不同),将 SD 和各个 CN 下采样阶段的同一层级的 SpatialTransformer 或 DownSample 的输出相加之后驻留在内存,之后和上采样阶段对应的 SpatialTransformer/UpSample 的输出 concat 在一起作为之后 ResBlock 的输出。
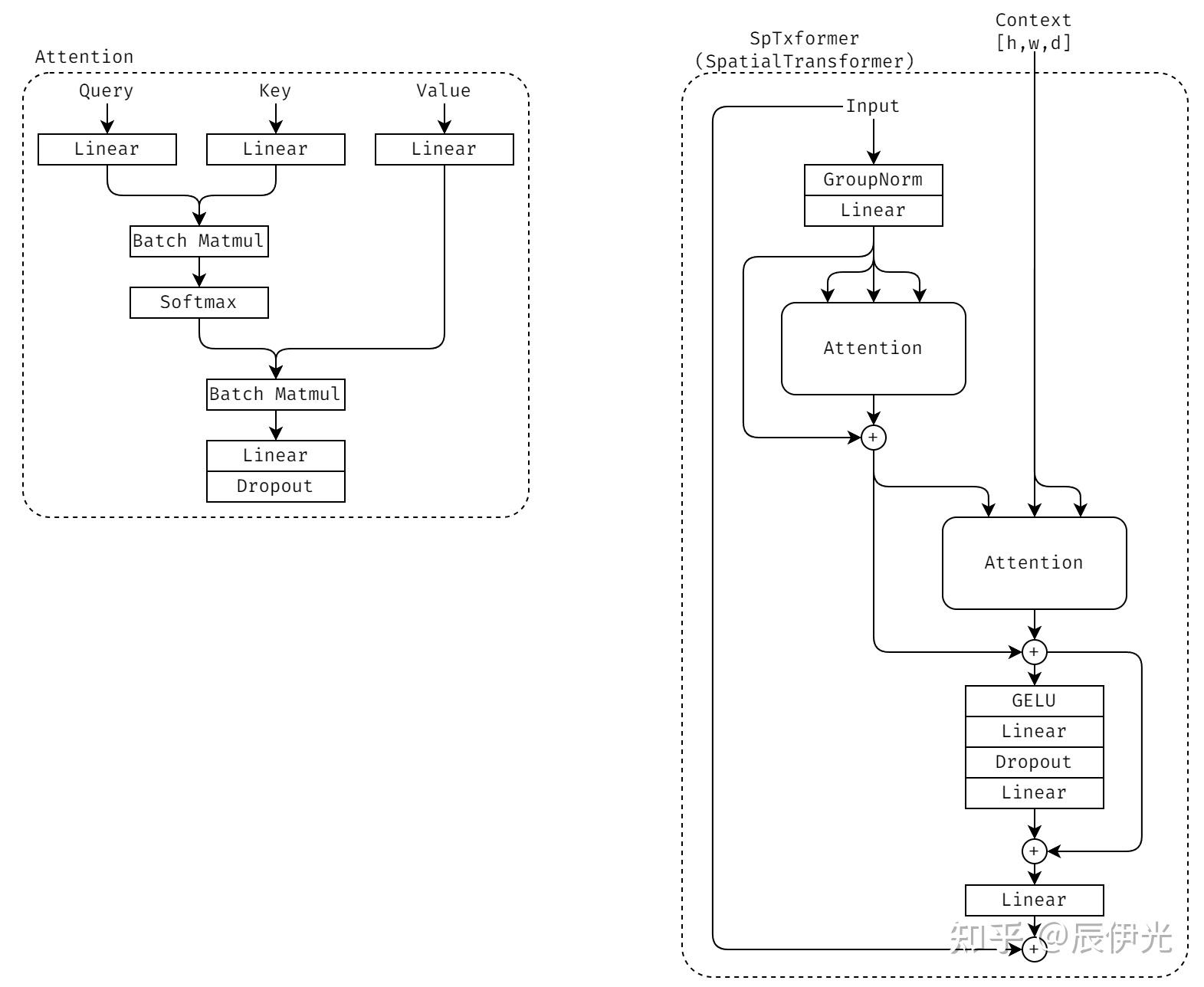
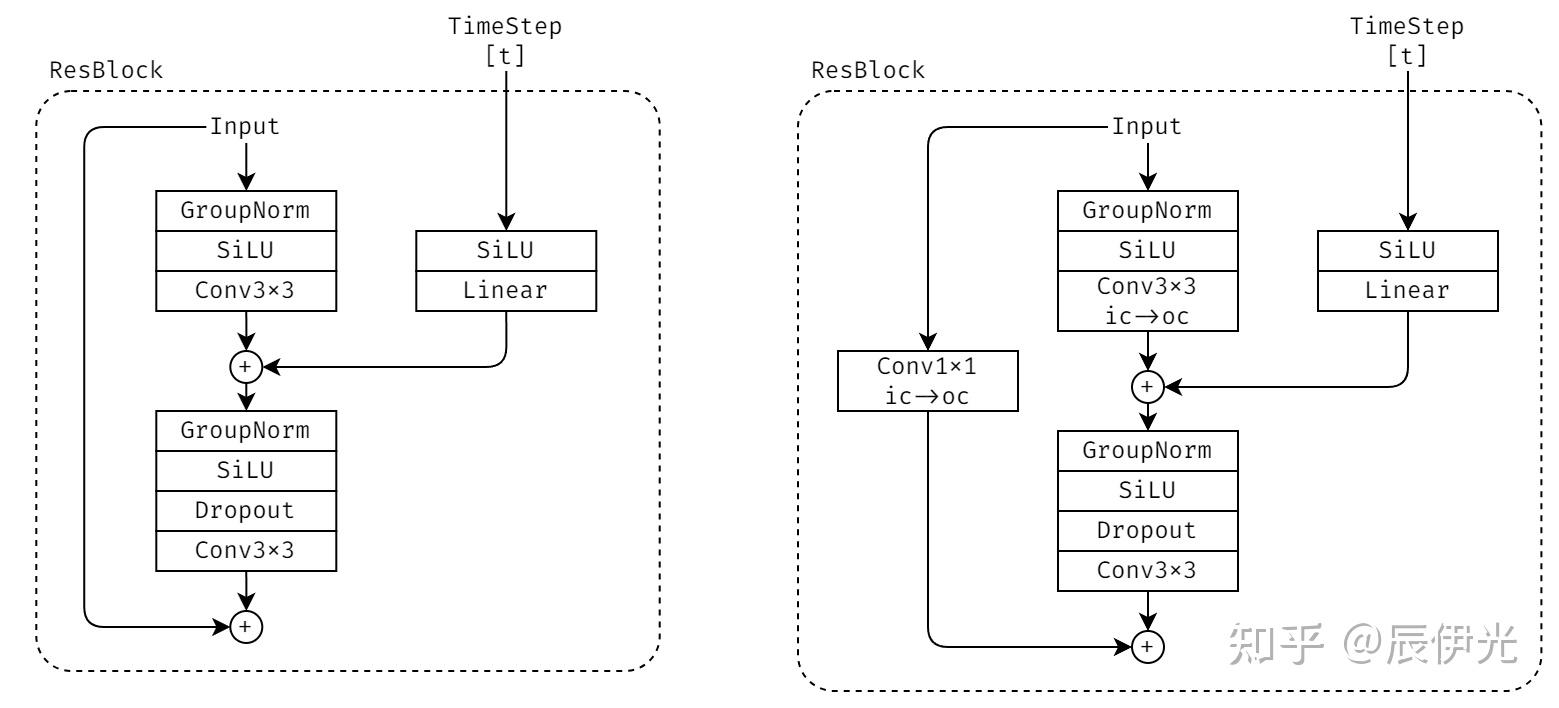
SD-UNet 中比较重要的两个模块是 ResBlock 和 SpatialTransformer。ResBlock 除了接收 latent-image 外,还会接收 time-step embedding 作为输入,两者通过 Conv3x3/Linear 映射后相加,再过一个 Conv3x3 和 residual addition,随后输出。
SpatialTransformer 接收 latent-image 和 context embedding(也就是用户输入的 prompt 编码后的 embedding)。SpatialTransformer 主要由 Self-Attention, Cross-Attention 和 Feed-Forward-Network / MLP 这三部分组成,其中 Cross-Attention 用于融合 latent-image 和 context/prompt。