if (alloc_flags & ALLOC_ZERO) memset(page2kva(pp), 0, PGSIZE);
return pp; }
page_free
这个比较简单,没什么要注意的点。
1 2 3 4 5 6 7 8 9 10 11
void page_free(struct PageInfo *pp) { // Fill this function in // Hint: You may want to panic if pp->pp_ref is nonzero or // pp->pp_link is not NULL. if(pp->pp_ref != 0 || pp->pp_link != NULL) panic("page_free"); pp->pp_link = page_free_list; page_free_list = pp; }
Exercise 2
Exercise 3
Q1: Assuming that the following JOS kernel code is correct, what type should variable x have, uintptr_t or physaddr_t?
1 2 3 4
mystery_t x; char* value = return_a_pointer(); *value = 10; x = (mystery_t) value;
int page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm) { // Fill this function in pte_t *pte; if (!(pte = pgdir_walk(pgdir, va, 1))) return -E_NO_MEM; pp->pp_ref++; page_remove(pgdir, va); *pte = page2pa(pp) | perm | PTE_P; return0; }
Exercise 5
page_map_region会默认置位页表项的PTE_P,因此将perm设为PTE_U即可。
关于page自身的映射,会在之后映射整个内核空间时进行。
1 2 3 4 5 6 7 8
////////////////////////////////////////////////////////////////////// // Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U);
////////////////////////////////////////////////////////////////////// // Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region( kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE, PADDR(bootstacktop) - KSTKSIZE, PTE_W);
这个比较简单。
1 2 3 4 5 6 7 8 9
////////////////////////////////////////////////////////////////////// // Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, KERNBASE, ~(uint32_t)0 - KERNBASE + 1, 0, PTE_W);
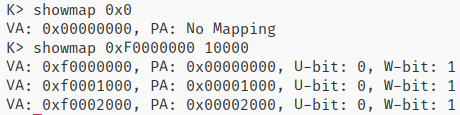
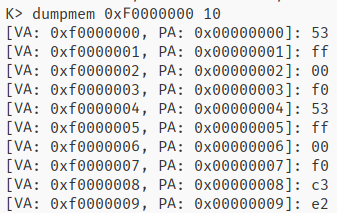
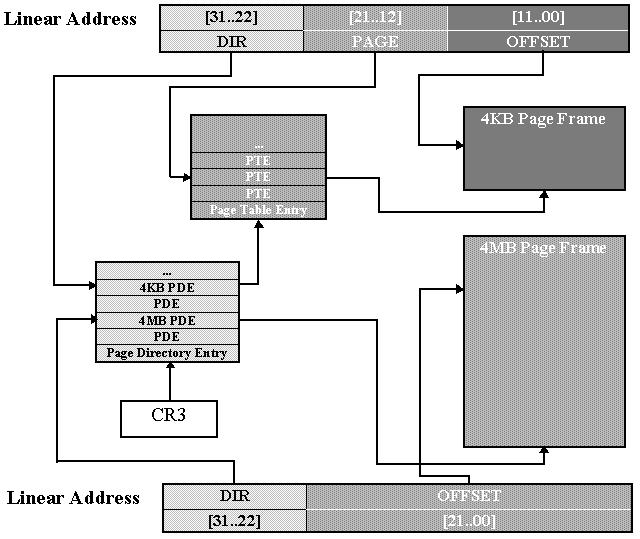
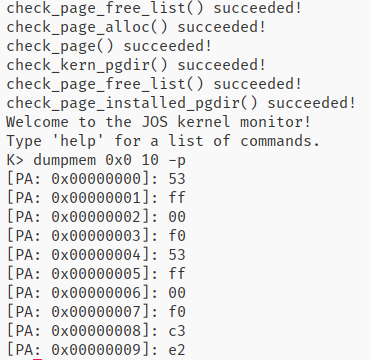
Q2: What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
Q3: We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
Q6: Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?